|
Чтобы понять роль математической статистики в области педагогики, достаточно
рассмотреть типичную схему педагогического эксперимента. Специалист,
занимающийся исследованиями в конкретной области педагогики или методики,
предложил новый подход к решению определенной задачи и должен доказать
справедливость своей рабочей гипотезы. Чаще всего единственное, что
он может сделать для этой цели,- проведение хорошо организованного эксперимента,
результаты которого убедительно доказывают выдвинутые предположения.
Традиционная схема эксперимента заключается в том, что набираются две
группы испытуемых: контрольная и экспериментальная, примерно одинаковые
по всем факторам, имеющим важное значение для цели исследования. Контрольная
группа подготавливается по традиционной методике, а экспериментальная
- с применением предлагаемых нововведений. После определенного этапа
подготовки проводится контрольное обследование, и по его результатам
судят об эффективности предлагаемой методики.
После проведения контрольных наблюдений исследователь получает фактический
материал, представляющий собой, как правило, большой объем числовых
данных. Методы описательной статистики позволяют провести классификацию
первичных данных, представить их в наиболее наглядной форме и получить
некоторые обобщающие показатели, которые дают возможность сравнивать
между собой различные данные и делать определенные выводы.
10.2. Генеральная совокупность и выборка 
Экспериментальные данные - это результаты измерения некоторых признаков
объектов, выбранных из большой совокупности объектов.
Часть объектов исследования, определенным образом выбранная из более
обширной совокупности, называется выборкой, а исходная совокупность,
из которой взята выборка,- генеральной (основной) совокупностью.
Исследования, в которых участвуют все без исключения объекты, составляющие
генеральную совокупность, называются сплошными исследованиями.
Может использоваться выборочный метод. Суть его в том, что для
обследования привлекается лишь выборка из генеральной совокупности,
но по результатам этого обследования судят о свойствах всей генеральной
совокупности.
Важнейшая характеристика выборки - объем выборки, т. е. число
элементов в ней; его принято обозначать символом n.
Предметом изучения в статистике являются изменяющиеся (варьирующиеся)
признаки, которые иногда называются статистическими. Они делятся
на качественные и количественные.
Качественными признаками объект обладает либо не обладает. Они
не поддаются непосредственному измерению (например, спортивная специализация,
квалификация, национальность, территориальная принадлежность и т. п.).
Количественные признаки представляют собой результаты подсчета или
измерения. В соответствии с этим они делятся на дискретные и непрерывные.
10.3. Эмпирические распределения
Эмпирические распределения представляют собой распределения
элементов выборки по значениям изучаемого признака. Построение эмпирических
распределений - необходимый этап применения статистических методов.
Эмпирические данные представляют собой данные, полученные в ходе эксперимента.
По эмпирическим данным, представляющим собой выборку из некоторой генеральной
совокупности, оценивают параметры, позволяющие описать всю генеральную
совокупность, определить интервал, в котором с заданным уровнем доверия
находится истинное значение оцениваемого параметра, а затем проверяют
те или иные утверждения и делают выводы о свойствах всей генеральной
совокупности.
Группировка представляет собой процесс систематизации, или упорядочения,
первичных данных с целью извлечь содержащуюся в них информацию. Группировка
заключается в распределении вариантов выборки по группам или интервалам
группировки, каждый из которых содержит некоторый диапазон значений
изучаемого признака.
Первая задача - определение числа интервалов группировки и ширины каждого
из них. Обычно предпочтительны интервалы одинаковой ширины, а при выборке
числа интервалов исходят из следующих соображений.
Группировка производится для того, чтобы построить эмпирическое распределение
и сформировать с его помощью предположения о форме распределения изучаемого
признака в генеральной совокупности, из которой взята выборка.
Поэтому вопрос о выборе числа и ширины интервалов группировки приходится
решать в каждом конкретном случае исходя из целей исследования, объема
выборки и степени варьирования признака в выборке. Однако приблизительно
число интервалов k можно оценить исходя только из объема выборки n.
Делается это одним из следующих способов:
1) по формуле Стержеса: k = 1 + 3,32·lg n;
2) с помощью таблицы:
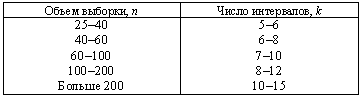
Если число интервалов выбрано, то ширина каждого из них определяется
по следующей формуле:
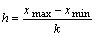 , ,
где h - ширина интервалов, xmax
и xmin - максимальная и минимальная
варианты выборки; xmax и xmin
определяются непосредственно по таблице исходных данных.
Теперь остается наметить границы интервалов группировки. Нижняя граница
первого интервала выбирается так, чтобы минимальная варианта выборки
xmin попадала примерно в середину
этого интервала. Отсюда нижняя граница первого интервала определяется
как
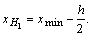
После того как намечены границы интервалов, остается распределить по
этим интервалам выборочные варианты. Для удобства последующей обработки
сгруппированных данных вычислим серединные значения интервалов
группировки xi, которые отстоят от
границ на величину, равную половине ширины интервалов, т. е.
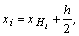 , ,
где - 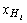 нижняя граница
i-го интервала. нижняя граница
i-го интервала.
Числа, показывающие, сколько раз варианты, относящиеся к каждому интервалу
группировки, встречаются в выборке, называются частотами интервалов.
Обозначим частоты символов ni. Общая
сумма всех частот всегда равна объему выборки n, что можно использовать
для проверки правильности составления статистической таблицы.
Накопленная частота интервала - это число, полученное последовательным
суммированием частот в направлении от первого интервала к последнему,
до того интервала включительно, для которого определяется накопленная
частота. Накопленные частоты обозначим 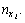
Частостью (относительной частотой) называется отношение частоты
к объему выборки. Обозначим частость символом fi:
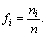
Накопленной частостью называется отношение накопленной частоты
к объему выборки. Обозначив накопленную частность как Fi, получаем :
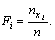
Сумма всех частостей всегда равна 1.
10.4.Числовые характеристики выборки
Вариационные ряды и графики эмпирических распределений дают наглядное
представление о том, как варьируется признак в выборочной совокупности.
Но они недостаточны для полной характеристики выборки, поскольку содержат
много деталей, охватить которые невозможно без применения обобщающих
числовых характеристик.
Числовые характеристики выборки дают количественное представление об
эмпирических данных и позволяют сравнивать их между собой. Наибольшее
практическое значение имеют характеристики положения, рассеяния и асимметрии
эмпирических распределений.
Среднее арифметическое представляет собой такое значение признака,
сумма отклонений выборочных значений признака от которого равна нулю.
Геометрический смысл среднего арифметического - точка
на оси х, которая является абсциссой центра масс гистограммы.
Среднее арифметическое может вычисляться как по необработанным первичным
данным, так и по результатам группировки этих данных.
Для несгруппированных данных:
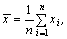
где n - объем выборки; xi - варианты выборки.
Для сгруппированных данных:
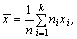
где n - объем выборки; k - число интервалов группировки; ni -
частоты интервалов; xi - срединные значения интервалов.
Медианой (Ме) называется такое значение признака X, когда одна
половина значений экспериментальных данных меньше ее, а вторая половина
- больше.
Для вычисления медианы несгруппированных данных выборку ранжируют,
т. е. располагают данные в порядке возрастания или убывания, и в ранжированной
выборке, содержащей n членов, ранг R (порядковый номер) медианы определяется
как 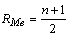 . Если четное число
членов в выборке, то медианой будет среднее арифметическое между двумя
центральными значениями членов выборки, порядковый номер которых больше
и меньше полученного значения ранга медианы. . Если четное число
членов в выборке, то медианой будет среднее арифметическое между двумя
центральными значениями членов выборки, порядковый номер которых больше
и меньше полученного значения ранга медианы.
Для нахождения медианы в случае сгруппированных данных находят интервал
группировки, в котором содержится медиана, путем подсчета накопленных
частостей. Медианным будет тот интервал, в котором накопленная частота
впервые окажется больше n/2 (n - объем выборки) или частость - больше
0,5. Внутри медианного интервала медиана определяется по следующей формуле:
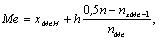
где хMeН - нижняя граница медианного интервала; h - ширина
интервалов группировки; nxMe-1 - накопленная частота интервала,
предшествующего медианному; nMe - частота медианного интервала.
Мода (Мо) представляет собой значение признака, встречающегося
в выборке наиболее часто.
Интервал группировки с наибольшей частотой называется модальным.
Для несгруппированных данных мода - это значение признака с наибольшей
частотой появления.
Для определения моды сгруппированных данных используется следующая
формула:
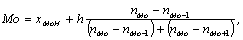 , ,
где xMoH - нижняя граница модального интервала, nMo
- частота интервала.
В случае, когда все значения в группе встречаются одинаково часто,
принято считать, что группа оценок не имеет моды.
Когда два соседних значения имеют одинаковую частоту и они больше частоты
любого другого значения, мода есть среднее этих двух значений.
Если два несмежных значения в группе имеют равные частоты и они больше
частот любого значения, то существуют две моды, а группа оценок является
бимодальной.
Вопросы
1. Приведите примеры использования математической статистики в исследованиях
по Вашей специальности.
2. В чем заключается выборочный метод исследования? В каких случаях
он применяется?
3. Что отражают числовые характеристики выборки?
4. Какая зависимость существует между значениями частоты и частости
интервала?
Ключевые слова
математическая статистика, выборка,
генеральная совокупность, объем выборки, эмпирические
распределения, группировка, интервалы, частота интервала,
частость, среднее арифметическое, медиана, мода.
|